
JavaScript 垃圾回收机制
引用计数垃圾收集
这是最初级的垃圾收集算法。此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
限制:循环引用标记—清除法
这个算法把“对象是否不再需要”简化定义为“对象是否可以获得”。
假定设置一个叫做根(root)的对象(在 Javascript 里,根是全局对象)。垃圾回收器将定期从根开始,找所有从根开始引用的对象,然后找这些对象引用的对象……从根开始,垃圾回收器将找到所有可以获得的对象和收集所有不能获得的对象。
这个算法比前一个要好,因为不可获得的对象不一定没有引用。修复了前一个算法的循环引用问题
限制:那些无法从根对象查询到的对象都将被清除,但是实际上很少会遇到类似的情况。
内存空间
数据结构:
堆(heap):树状结构,类似书本,根据书名就能找到书 栈(stack):后进先出 队列(queue):先进先出
数据类型
- 基础数据类型(值存储在栈中): Undefined、Null、Boolean、Number、String、Symbol(ES6)
- 引用数据类型(值存放在堆中): Array、Object
内存空间管理
- JavaScript 的内存生命周期
- 分配你所需要的内存: var a = 20
- 使用分配到的内存(读、写): console.log(a)
- 不需要时将其释放、归还: a = null (标记清除算法: a = null 其实仅仅只是做了一个释放引用的操作,让 a 原本对应的值失去引用,脱离执行环境,这个值会在下一次垃圾收集器执行操作时被找到并释放。而在适当的时候解除引用,是为页面获得更好性能的一个重要方式。)
- JavaScript 自动垃圾收集机制
在局部作用域中,当函数执行完毕,局部变量也就没有存在的必要了,因此垃圾收集器很容易做出判断并回收。 但是全局变量什么时候需要自动释放内存空间则很难判断,因此在我们的开发中,需要尽量避免使用全局变量。
执行上下文(EC)
每次当控制器转到可执行代码的时候,就会进入一个执行上下文。执行上下文可以理解为当前代码的执行环境,它会形成一个作用域。JavaScript 中的运行环境大概包括三种情况。
- 全局环境:JavaScript 代码运行起来会首先进入该环境
- 函数环境:当函数被调用执行时,会进入当前函数中执行代码
- eval(不建议使用,可忽略)
因此在一个 JavaScript 程序中,必定会产生多个执行上下文,JavaScript 引擎会以栈的方式来处理它们,这个栈,我们称其为函数调用栈(call stack)。栈底永远都是全局上下文,而栈顶就是当前正在执行的上下文。
特点
- 单线程
- 同步执行,只有栈顶的上下文处于执行中,其他上下文需要等待
- 全局上下文只有唯一的一个,它在浏览器关闭时出栈
- 函数的执行上下文的个数没有限制
- 每次某个函数被调用,就会有个新的执行上下文为其创建,即使是调用的自身函数,也是如此。
生命周期
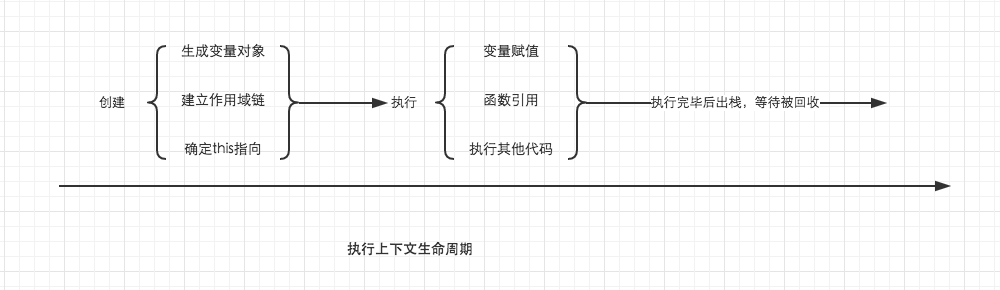
- 创建阶段: 创建变量对象(VO)->建立作用域链(ScopeChain)->确定 this 指向
- 代码执行阶段:变量赋值、函数引用、执行其他代码
变量对象
创建过程
- 建立 arguments 对象。检查当前上下文中的参数,建立该对象下的属性与属性值。
- 检查当前上下文的函数声明,也就是使用 function 关键字声明的函数。在变量对象中以函数名建立一个属性,属性值为指向该函数所在内存地址的引用。如果函数名的属性已经存在,那么该属性将会被新的引用所覆盖。(函数声明提前)
- 检查当前上下文中的变量声明,每找到一个变量声明,就在变量对象中以变量名建立一个属性,属性值为 undefined。如果该变量名的属性已经存在,为了防止同名的函数被修改为 undefined,则会直接跳过,原属性值不会被修改。
未进入执行阶段之前,变量对象中的属性都不能访问!但是进入执行阶段之后,变量对象转变为了活动对象,里面的属性都能被访问了,然后开始进行执行阶段的操作。
注: 变量对象和活动对象,其实都是同一个对象,只是出于执行上下文的不同生命周期,只有处于函数调用栈栈顶的执行上下文的变量对象才会变成活动对象。
3.作用域与闭包
作用域与执行上下文区别
JavaScript 代码的整个执行过程,分为两个阶段,代码编译阶段与代码执行阶段。编译阶段由编译器完成,将代码翻译成可执行代码,这个阶段作用域规则会确定。执行阶段由引擎完成,主要任务是执行可执行代码,执行上下文在这个阶段创建
闭包
闭包,就是 一个函数 与其 被创建时所带有的作用域对象 的组合。闭包允许你保存状态。
它由两部分组成。执行上下文(代号 A),以及在该执行上下文中创建的函数(代号 B)。
当 B 执行时,如果访问了 A 中变量对象中的值,那么闭包就会产生。
function makeAdder(a) {
function adder(b) {
return a + b;
}
return adder;
}
var add5 = makeAdder(5);
var add20 = makeAdder(20);
add5(6); // ?
add20(7); // ?
当新函数 add5、add20 被创建的时候,新函数自带一个参数 5、20;
新函数被调用的时候,又接收了一个参数 6、7。最终,新函数被调用的时候,前一个参数便会和由外层传入的后一个参数相加。
原理:ES6 之前,js 只有全局作用域和局部作用域(函数)没有块级作用域,每当 JavaScript 执行一个函数时,都会创建一个作用域对象(scope object),用来保存在这个函数中创建的局部变量。它使一切被传入函数的变量进行初始化(初始化后,它包含一切被传入函数的变量)。这与那些保存的所有全局变量和函数的全局对象(global object)相类似,但仍有一些很重要的区别:第一,每次函数被执行的时候,就会创建一个新的,特定的作用域对象;第二,与全局对象(如浏览器的 window 对象)不同的是,你不能从 JavaScript 代码中直接访问作用域对象,也没有 可以遍历当前作用域对象中的属性的方法。
所以,当调用 makeAdder 时,解释器创建了一个作用域对象,它带有一个属性:a,这个属性被当作参数传入 makeAdder 函数。然后 makeAdder 返回一个新创建的函数 adder。通常,JavaScript 的垃圾回收器会在这时回收 makeAdder 创建的作用域对象(暂记为 A),但是,makeAdder 的返回值,新函数 adder,拥有一个指向作用域对象 A 的引用。最终,作用域对象 A 不会被垃圾回收器回收,直到没有任何引用指向新函数 adder。
如果一个函数由一个函数调用,而另一个函数又调用了另一个函数,则将创建对外部词汇环境的引用链。该链称为作用域链(scope chain)。它和 JavaScript 的对象系统使用的原型链(prototype)相类似。
使用场景:每当需要与函数关联私有状态时,闭包都是有用的。JavaScript 直到 2015 年才使用类语法,并且仍然没有私有字段语法。封闭件可满足此需求。
值得注意:
- 每当在 JavaScript 中声明函数时,都会创建一个闭包。此闭包用于在调用函数时配置执行上下文。
- 每次调用函数时都会创建一组新的局部变量。
- 外部函数内部的状态对于返回的内部函数隐式可用,即使在外部函数完成执行之后也是如此。
- JavaScript 中的闭包就像在函数声明时保留对作用域的引用(而不是副本),这继而保留对外部作用域的引用,依此类推,一直指向全局对象的顶部范围链。
// demo07
function foo() {
var a = 10;
function fn1() {
return a;
}
function fn2() {
return 10;
}
fn2();
}
foo();
虽然 fn2 并没有访问到 foo 的变量,但是 foo 执行时仍然变成了闭包。而当我将 fn1 的声明去掉时,闭包便不会出现了。
那么结合这个特殊的例子,我们可以这样这样定义闭包。
闭包是指这样的作用域(foo),它包含有一个函数(fn1),这个函数(fn1)可以调用被这个作用域所封闭的变量(a)、函数、或者闭包等内容。通常我们通过闭包所对应的函数来获得对闭包的访问。
总结:
- 闭包是在函数被调用执行的时候才被确认创建的。
- 闭包的形成,与作用域链的访问顺序有直接关系。
- 只有内部函数访问了上层作用域链中的变量对象时,才会形成闭包,因此,我们可以利用闭包来访问函数内部的变量。
形成条件
- 在函数(A)内部创建新的函数
- 新的函数在执行时,访问了函数(A)的变量对象。
闭包阻止垃圾回收机制释放内存函数的执行上下文,在执行完毕之后,生命周期结束,那么该函数的执行上下文就会失去引用。其占用的内存空间很快就会被垃圾回收器释放。可是闭包的存在,会阻止这一过程。
事件循环
- 宏任务: script(整体代码)、setTimeout、setInterval、setImmediate、I/O、UI rendering
- 微任务: process.nextTick、promise、 Object.observe、MutationObserve
- 任务优先级: process.nextTick > promise.then > setTimeout > setImmediate
MutationObserve:监视对 DOM 树所做更改的能力。
记忆:微任务是跟屁虫,一直跟着当前宏任务后面,代码执行到一个微任务就跟上,一个接一个
- setTimeout/Promise等我们称之为任务源。而进入任务队列的是他们指定的具体执行任务。
// setTimeout中的回调函数才是进入任务队列的任务 setTimeout(function() { console.log('xxxx'); }) // 非常多的同学对于setTimeout的理解存在偏差。所以大概说一下误解: // setTimeout作为一个任务分发器,这个函数会立即执行,而它所要分发的任务,也就是它的第一个参数,才是延迟执行 - 来自不同任务源的任务会进入到不同的任务队列。其中setTimeout与setInterval是同源的。
- 事件循环的顺序,决定了JavaScript代码的执行顺序。
它从script(整体代码)开始第一次循环。之后全局上下文进入函数调用栈。直到调用栈清空(只剩全局),然后执行所有的micro-task。当所有可执行的micro-task执行完毕之后。循环再次从macro-task开始,找到其中一个任务队列执行完毕,然后再执行所有的micro-task,这样一直循环下去。
函数与函数式编程
函数参数传递方式:按值传递
对象作为函数参数时,传递的是对象的引用地址
函数式编程期望一个函数有输入,也有输出。
function setBackgroundColor(ele, color) {
ele.style.backgroundColor = color;
return color;
}
// 多处使用
var ele = document.querySelector(".test");
setBackgroundColor(ele, "red");
setBackgroundColor(ele, "#ccc");
**纯函数:**只要是同样的参数传入,返回的结果一定是相等的。
函数式编程强调没有”副作用”,意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。
var source = [1, 2, 3, 4, 5];
source.slice(1, 3); // 纯函数 返回[2, 3] source不变
source.splice(1, 3); // 不纯的 返回[2, 3, 4] source被改变
source.pop(); // 不纯的
source.push(6); // 不纯的
source.shift(); // 不纯的
source.unshift(1); // 不纯的
source.reverse(); // 不纯的
// 我也不能短时间知道现在source被改变成了什么样子,干脆重新约定一下
source = [1, 2, 3, 4, 5];
source.concat([6, 7]); // 纯函数 返回[1, 2, 3, 4, 5, 6, 7] source不变
source.join("-"); // 纯函数 返回1-2-3-4-5 source不变
函数柯里化
柯里化是指这样一个函数(假设叫做 createCurry),他接收函数 A 作为参数,运行后能够返回一个新的函数。并且这个新的函数能够处理函数 A 的剩余参数。
var _A = createCurry(A);
_A(1, 2, 3);
_A(1, 2)(3);
_A(1)(2, 3);
_A(1)(2)(3);
A(1, 2, 3);
// 以上都是等价的
// 简单实现
function createCurry(func, curryArgs) {
// arity的形参个数
var arity = func.length;
var curryArgs = curryArgs || [];
return function () {
/// _args当前匿名函数形参
var _args = [].slice.call(arguments);
[].unshift.apply(_args, curryArgs);
// 如果参数个数小于最初的func.length,则递归调用,继续收集参数
if (_args.length < arity) {
return createCurry.call(this, func, _args);
}
// 参数收集完毕,则执行func
return func.apply(this, _args);
};
}
// 测试一下
var add = function (a, b, c) {
return a + b + c;
};
var _add = createCurry(add);
_add(1)(2)(3);
为什么要用柯里化?
柯里化能够帮助我们应对更多更复杂的场景。
假如这个在我们项目中会调用多次的操作是将数组的每一项都转化为百分比 1 –> 100%。
普通思维下我们可以这样来封装。
function getNewArray(array) {
return array.map(function (item) {
return item * 100 + "%";
});
}
getNewArray([1, 2, 3, 0.12]); // ['100%', '200%', '300%', '12%'];
而如果借助柯里化来二次封装这样的逻辑,则会如下实现:
function _map(func, array) {
return array.map(func);
}
var _getNewArray = createCurry(_map);
var getPercentNumber = _getNewArray(function (item) {
return item * 100 + "%";
});
var getMoney = _getNewArray(function (item) {
return `$${item}.00 `;
});
getPercentNumber([1, 2, 3, 0.12]); // ['100%', '200%', '300%', '12%'];
getMoney([10, 30, 10.5]); // ["$10.00 ", "$30.00 ", "$10.5.00 "]
箭头函数
function fn(x) {
return function (y) {
return x + y;
};
}
let fn2 = (x) => {
return (y) => x + y;
};
// let fn3 = (x) => (y) => x + y;
let fn4 = (x) => (y) =>{
console.log('x ',x) // x 1
console.log('y ',y) // y 2
return x + y
};
const result = fn4(1)(2)
console.log(result) // 3
